因为直接在博客上打有点麻烦,就直接放图片了,想要pdf和latex版本可以问我要
阿里云CDN/DCDN
最近突发奇想用CDN加速个人博客,因为该服务器访问速度太慢,加载图片/文件等速度让我忍不了,但是直接升级带宽又太贵,就想试试阿里云的CDN,当然你用别的云平台服务也是可以的。
首先你需要购入阿里云CDN/DCDN资源包(下行流量):中国内地通用流量包等,100GB 20元这样一个定价。但是此时如果你想加速443即使用https还需要购入静态HTTPS请求包1000w次40元这样一个定价,当然你如果只想加速80端口即http就不需要购入静态HTTPS请求包。到这还没完,你还需要购入动态请求包,即抵扣动态https和http动态请求,100w次14元这样一个定价。不得不说阿里赚钱有一手,诶,买一个还不够,要买好多个。
很多人买了CDN流量包但是加速不了网站,显示https不安全就是没有购买和配置https的原因。
CDN和DCDN配置规则相似,以下为我配置DSDN的方法流程:
- 点击添加域名
- 加速域名 输入:*.pancake2021.work
- 业务类型:DCDN即为全站加速,个人博客也可用小文件照片选项,区别请见下文
- 加速区域:仅中国内地
- 点击新增源站信息:
类型:ip
IP:即为你服务器IP地址(我自己IP就不写了哈哈)
端口:443(我博客没有配置80所以也就懒得搞了) - 配置CNAME:
打开域名解析系统(因为全站加速我暂时只需要www与@的主机记录值,我并没有把*作为主机记录,取而代之的是把*直接访问服务器地址绕开CDN个人觉得反而更快)
因为原来可能配置了www和@的A记录类型,可以把其改成CNAME记录类型否则会冲突,把全站加速给你的CNAME记录值填进去。不用担心改了www和@之后访问不到网站,CDN会自动返回请求给你服务器地址。 - 验证CNAME:
DNS解析响应不会那么快,可能得等5-10min取决于你的TTL时长,不要着急验证不通过。
我上述步骤设置的*.pancake2021.work 域名阿里云CNAME检验会不通过,这就需要自己ping一下你的域名比如:ping www.pancake2021.work 是否会返回你填进去该域名下的CNAME记录值域名,若相同则配置完成。 - 配置https:
域名管理-选择你的域名进入-HTTPS配置-修改配置-开启
你可以自己申请也可以用原来自己申请的阿里云的免费证书,我是直接自定义上传的。
从你的阿里云免费ssl证书中下载根证书,把证书复制进去。
至此完成所有步骤,以下为可选步骤。 - 缓存配置可以不需要你服务器来配置url重写,能直接在这里写帮助你重定向。
- 动态加速规则,因为wordpress也就那么点文件夹在动态路径中我加入了:
/wp-content/*
/wp-admin/*
注意:因为配置了*.pancake2021.work为二级泛域名,不能加速一级域名,所以wordpress所需要加载图片要用到的pancake2021.work一级域名需要再行进行配置,即在上述第二部中输入pancake2021.work即可。
CDN和DCDN的区别:DCDN可以说是CDN的升级版,具体速度差别我这种小用户也感觉不出来,但是说实话我更推荐CDN因为CDN比DCDN多了一个带宽限制的功能,对防止攻击更加有效,DCDN只有购买昂贵的防DDOS 攻击才行,很多DCDN防护要么是贵,要没是功能未上线,这一点上我觉得阿里云可以改进一下。
嘎嘣脆的树莓派系统
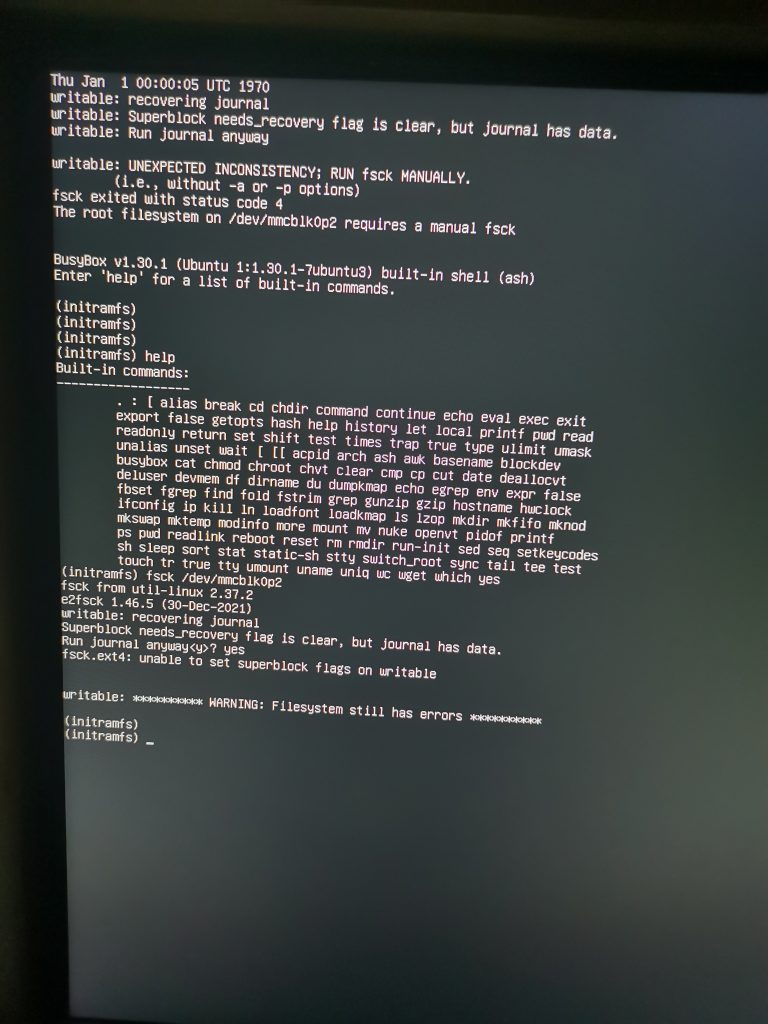
就是说再也不敢不shutdown就拔电源了,这张树莓派sd卡彻底废了,无法恢复的那种 🙁
连带着 code-server 和 jupyter 消失在了历史的长河中。里面的 leetcode 代码和以前做的一些 python 学习资料连带着g了,我真的会谢
强化学习 Pytorch
个人强化学习过程,Q-learning(基础)-> DQN -> AC -> A2C / A3C -> DDPG -> TD3
DQN
算法简要说明:采用经验回放与神经网络对Q-learning进行优化,使其能够输入连续的数,并更好的利用数据。
参考代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 |
""" https://www.bilibili.com/read/cv13271394 """ import torch import torch.nn as nn import torch.nn.functional as F import numpy as np import gym # 项目参数(超参数) BATCH_SIZE = 32 # 随机抽取BATCH_SIZE条数据。 LR = 0.01 # 学习率 (learning rate) EPSILON = 0.9 # # 最优选择动作百分比 (greedy policy) GAMMA = 0.9 # 奖励递减参数 (reward discount) TARGET_REPLACE_ITER = 100 # Q 现实网络的更新频率 (target update frequency) MEMORY_CAPACITY = 2000 # 记忆库大小 env = gym.make('CartPole-v0') # 导入模拟实验,创建一个实验环境 env = env.unwrapped # 还原env的原始配置, if 不还原就会限制step的次数(<200) 还原后就不受限制了 N_ACTIONS = env.action_space.n # 杆子能做的动作 # 查看这个环境中可用的action有多少个,返回int N_STATES = env.observation_space.shape[0] # 杆子能获取的环境信息数 #查看这个环境中observation的特征有多少个,返回int ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape # to confirm the shape # 定义神经网络class class Net(nn.Module): def __init__(self, ): super(Net, self).__init__() # 这里以一个动作为作为观测值进行输入,然后把他们输出给50个神经元 # N_STATES 与 图像的特征值个数有关 self.fc1 = nn.Linear(N_STATES, 50) # N_ACTIONS 与 能做的动作个数有关 self.fc1.weight.data.normal_(0, 0.1) # 初始化权重,用二值分布来随机生成参数的值 # 经过50个神经元运算过后的数据, 把每个动作的价值作为输出。 # self.out = nn.Linear(50, N_ACTIONS) # 做出每个动作后,每个动作的价值作为输出。 self.out.weight.data.normal_(0, 0.1) # 初始化权重,用二值分布来随机生成参数的值 # 输入-当前状态 action --Net网络--输出--》 所有动作价值 def forward(self, x): x = self.fc1(x) x = F.relu(x) actions_value = self.out(x) return actions_value net = Net() # 定义DQN 网络class class DQN(object): def __init__(self): # 建立一个评估网络(eaval) 和 Q现实网络 (target) self.eval_net, self.target_net = Net(), Net() # 用来记录学习到第几步了 self.learn_step_counter = 0 # for target updating # 用来记录当前指到数据库的第几个数据了 self.memory_counter = 0 # for storing memory # MEMORY_CAPACITY = 2000 , 限制了数据库只能记住2000个。前面的会被后面的覆盖 # 一次存储的数据量有多大 MEMORY_CAPACITY 确定了memory数据库有多大 , 后面的 N_STATES * 2 + 2 是因为 两个 N_STATES(在这里是4格子,因为N_STATES就为4) + 一个 action动作(1格) + 一个 rward(奖励) self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # initialize memory # 优化器,优化评估神经网络(仅优化eval) self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) self.loss_func = nn.MSELoss() # 进行选择动作 def choose_action(self, x): # 获取输入 x = torch.unsqueeze(torch.FloatTensor(x), 0) # input only one sample # 在大部分情况,我们选择 去max-value if np.random.uniform() < EPSILON: # greedy # 随机结果是否大于EPSILON(0.9) actions_value = self.eval_net.forward(x) # if 取max方法选择执行动作 action = torch.max(actions_value, 1)[1].data.numpy() action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # return the argmax index # 在少部分情况,我们选择 随机选择 (变异) else: # random # not if 取随机方法执行动作。 action = np.random.randint(0, N_ACTIONS) action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE) # 输入动作action return action # 存储数据 # 本次状态,执行的动作,获得的奖励分, 完成动作后产生的下一个状态。 # 存储这四个值 def store_transition(self, s, a, r, s_): # 把所有的记忆捆在一起,以 np类型 # 把 三个矩阵 s ,[a,r] ,s_ 平铺在一行 [a,r]是因为 他们都是 int 没有 [] 就无法平铺 ,并不代表把他们捆在一起了 transition = np.hstack((s, [a, r], s_)) # index 是 这一次录入的数据在 3000 的哪一个位置 index = self.memory_counter % MEMORY_CAPACITY # 如果,记忆超过上线,我们重新索引。即覆盖老的记忆。 self.memory[index, :] = transition self.memory_counter += 1 # 从存储学习数据 # target 是 达到次数后更新, eval net是 每次learn 就进行更新 def learn(self): # target parameter update 是否要更新现实网络 # target Q现实网络 要间隔多少步跟新一下。 如果learn步数 达到 TARGET_REPLACE_ITER 就进行一次更新 if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # 把最新的eval 预测网络 推 给target Q现实网络 # 也就是变成,还未变化的eval网 self.target_net.load_state_dict(self.eval_net.state_dict()) # 把 eval的所有参数 赋值到 target中 self.learn_step_counter += 1 # eval net是 每次learn 就进行更新 # 更新逻辑就是从记忆库中随机抽取BATCH_SIZE个(32个)数据。 sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) # 从 数据库中 随机 抽取 BATCH_SIZE条数据 b_memory = self.memory[sample_index, :] # 把这BATCH_SIZE个(32个)数据打包 # 下面这些变量是 32个数据打包的变量 b_s = torch.FloatTensor(b_memory[:, :N_STATES]) # 32个记忆的包,包里是(当时的状态) b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES + 1].astype(int)) # 32个记忆的包,包里是(当时做出的动作) b_r = torch.FloatTensor(b_memory[:, N_STATES + 1:N_STATES + 2]) # 32个记忆的包,包里是 (当初获得的奖励) b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:]) # 32个记忆的包,包里是 (执行动作后,下一个动作的状态) # q_eval w.r.t the action in experience # q_eval的学习过程 # self.eval_net(b_s).gather(1, b_a) 输入我们包(32条)中的所有状态 并得到(32条)所有状态的所有动作价值, .gather(1,b_a) 只取这32个状态中 的 每一个状态的最大值 # 预期价值计算 == 随机32条数据中的最大值 q_eval = self.eval_net(b_s).gather(1, b_a) # shape (batch, 1) # 输入下一个状态 进入我们的现实网络 输出下一个动作的价值 .detach() 阻止网络反向传递,我们的target需要自己定义该如何更新,它的更新在learn那一步 q_next = self.target_net(b_s_).detach() # detach from graph, don't backpropagate # q_target 实际价值的计算 == 当前价值 + GAMMA(未来价值递减参数) * 未来的价值 q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # shape (batch, 1) # q_eval预测值, q_target真实值 loss = self.loss_func(q_eval, q_target) # 根据误差,去优化我们eval网 # 因为这是eval的优化器 self.optimizer.zero_grad() loss.backward() self.optimizer.step() # 运行总流程!!! dqn = DQN() # 实例化DQN类,也就是实例化这个强化学习网络 print('\nCollecting experience...') # 进行2100次训练 for i_episode in range(2100): # 每一次新的训练 # 开始,会重置我们的env, 每一次训练的环境都是独立的而完全一样的,只有网络记忆是一直留存的 s = env.reset() # 获得初始化 observation 环境特征 ep_r = 0 # 作为一个计数变量,来统计我第n次训练。 完成所有动作的分的总和 # 开始实验循环 # 只有env认为 这个实验死了,才会结束循环 while True: env.render() # 刷新环境状态 , 使得screen 可以联系的动 # 根据 输入的环境特征s 输出选择动作 a a = dqn.choose_action(s) # 通过当前选择的动作得到,执行这个动作后的结果也就是,下一步状态s_(也就是observation) 特征值矩阵 , # 立即回报r 返回动作执行的奖励 , r是一个float类型 # 终止状态 done (done=True时环境结束) , done 是 bool # 调试信息 info (一般没用) s_, r, done, info = env.step(a) # env.step(a) 是执行 a 动作 它返回的就是 s_ ,r ,done , info # 到这里,预测流程就结束........ # 下面是对预测的结果进行评价与修正....... # 因为 env.step(a)返回的rward难学,所以下面是对rward的规则进行调整,让训练时间短一点 # 方便理解,可以认为它还是r (返回执行动作的奖励) x, x_dot, theta, theta_dot = s_ r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8 r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5 r = r1 + r2 ##### # 存储数据 # 每完成一个动作,记忆存储数据一次 dqn.store_transition(s, a, r, s_) # 最终得分 = 每一步得分 求合 # 最后打印它,看这一次训练,最终得分是多少(可知道总分,但不知道执行了多少个动作,当然你也可以做一个计算器算一下,不难) ep_r += r # 假如我们总训练2000次, # 在训练第i_episode(200)次后,我们数据库中累计的信息超过3000条后。 # 这个时 dqn中的数据库中的记忆条数 大于 数据库的容量 if dqn.memory_counter > MEMORY_CAPACITY: # 它就会开对去学习。 # eavl 每学一次就会更新一次 # 它的更新思路是从我历史记忆中随机抽取数据。 #学习一次,就在数据库中随机挑选BATCH_SIZE(32条) 进行打包 # 而target不一样,它是在我们学习过程中到一定频率(TARGET_REPLACE_ITER,来决定)。它的思路是:target网会去复制eval网的参数 dqn.learn() # 在满足 大于数据库容量的条件下,我再看env.step(a) 返回的done,env是否认为实验结束了 if done: # 如果done=True , 打印这是第n次训练和这次训练的总分 # 打印这是i_episode次训练 , Ep_r代表这次的总分 print('Ep: ', i_episode, '| Ep_r: ', round(ep_r, 2)) # if done=Truue # env判断游戏结束跳出while循环,开始进行下一次训练 if done: break # env判断游戏没有结束进行while循环,下次状态变成当前状态, 开始走下一步。 s = s_ |
Actor Critic
算法简要说明:Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率。
说明:现已改正 CSDN 上错误代码并经行优化。Github上代码流程为跑完一次历程再进行网络优化,并且Actor和Critic共用同一个optimizer和loss,CSDN 上代码流程为原论文流程,即一边跑历程,一边训练网络,并且Actor和Critic具有不一样的optimizer和loss。
对比:原论文流程,即 CSDN 代码流程网络训练较慢,但收敛可能较快。但在跑 CartPole-v1 的时候效果还是Github 代码优异,只能说具体问题可以都试试,选择最优的代码流程。
CSDN 参考代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 |
""" https://blog.csdn.net/qq_34003876/article/details/107477426 """ import torch import torch.nn as nn import torch.nn.functional as F import gym import time import numpy as np # Hyper Parameters for Actor GAMMA = 0.95 # discount factor LR = 0.01 # learning rate # Use GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") torch.backends.cudnn.enabled = False # 非确定性算法 class ActorNetwork(nn.Module): def __init__(self, state_dim, action_dim): super(ActorNetwork, self).__init__() self.fc1 = nn.Linear(state_dim, 20) self.fc2 = nn.Linear(20, action_dim) def forward(self, x): out = torch.relu(self.fc1(x)) out = self.fc2(out) out = torch.softmax(out, dim=0) return out def initialize_weights(self): for m in self.modules(): nn.init.normal_(m.weight.data, 0, 0.1) nn.init.constant_(m.bias.data, 0.01) class Actor(object): # dqn Agent def __init__(self, env): # 初始化 # 状态空间和动作空间的维度 self.state_dim = env.observation_space.shape[0] self.action_dim = env.action_space.n # init network parameters self.network = ActorNetwork(state_dim=self.state_dim, action_dim=self.action_dim).to(device) self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR) # init some parameters self.time_step = 0 def choose_action(self, observation): observation = torch.FloatTensor(observation).to(device) network_output = self.network.forward(observation).data.numpy() action = np.random.choice(range(network_output.shape[0]), p=network_output) return action def learn(self, state, action, td_error): self.time_step += 1 # Step 1: 前向传播 softmax_input = self.network.forward(torch.FloatTensor(state).to(device)).unsqueeze(0) action = torch.LongTensor([action]).to(device) neg_log_prob = F.cross_entropy(input=softmax_input, target=action) # Step 2: 反向传播 # 这里需要最大化当前策略的价值,因此需要最大化neg_log_prob * tf_error,即最小化-neg_log_prob * td_error loss_a = neg_log_prob * td_error self.optimizer.zero_grad() loss_a.backward() self.optimizer.step() # Hyper Parameters for Critic EPSILON = 0.01 # final value of epsilon REPLAY_SIZE = 10000 # experience replay buffer size BATCH_SIZE = 32 # size of minibatch REPLACE_TARGET_FREQ = 10 # frequency to update target Q network class QNetwork(nn.Module): def __init__(self, state_dim, action_dim): super(QNetwork, self).__init__() self.fc1 = nn.Linear(state_dim, 20) self.fc2 = nn.Linear(20, 1) # 这个地方和之前略有区别,输出不是动作维度,而是一维 def forward(self, x): out = F.relu(self.fc1(x)) out = self.fc2(out) return out def initialize_weights(self): for m in self.modules(): nn.init.normal_(m.weight.data, 0, 0.1) nn.init.constant_(m.bias.data, 0.01) class Critic(object): def __init__(self, env): # 状态空间和动作空间的维度 self.state_dim = env.observation_space.shape[0] self.action_dim = env.action_space.n # init network parameters self.network = QNetwork(state_dim=self.state_dim, action_dim=self.action_dim).to(device) self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR) self.loss_func = nn.MSELoss() # init some parameters self.time_step = 0 self.epsilon = EPSILON # epsilon值是随机不断变小的 def train_Q_network(self, state, reward, next_state): s, s_ = torch.FloatTensor(state).to(device), torch.FloatTensor(next_state).to(device) # 前向传播 v = self.network.forward(s) # v(s) v_ = self.network.forward(s_) # v(s') # 反向传播 loss_q = self.loss_func(GAMMA * reward + v_, v) self.optimizer.zero_grad() loss_q.backward() self.optimizer.step() with torch.no_grad(): td_error = GAMMA * reward + v_ - v return td_error # Hyper Parameters ENV_NAME = 'CartPole-v0' EPISODE = 3000 # Episode limitation STEP = 3000 # Step limitation in an episode TEST = 10 # The number of experiment test every 100 episode def main(): # initialize OpenAI Gym env and dqn agent env = gym.make(ENV_NAME) actor = Actor(env) critic = Critic(env) for episode in range(EPISODE): # initialize task state = env.reset() # Train for step in range(STEP): action = actor.choose_action(state) # SoftMax概率选择action next_state, reward, done, _ = env.step(action) td_error = critic.train_Q_network(state, reward, next_state) # gradient = grad[r + gamma * V(s_) - V(s)] actor.learn(state, action, td_error) # true_gradient = grad[logPi(s,a) * td_error] state = next_state if done: break # Test every 100 episodes if episode % 100 == 0: total_reward = 0 for i in range(TEST): state = env.reset() for j in range(STEP): env.render() action = actor.choose_action(state) # direct action for test state, reward, done, _ = env.step(action) total_reward += reward if done: break ave_reward = total_reward / TEST print('episode: ', episode, 'Evaluation Average Reward:', ave_reward) if __name__ == '__main__': time_start = time.time() main() time_end = time.time() print('Total time is ', time_end - time_start, 's') |
Github 参考代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 |
""" https://github.com/pytorch/examples/blob/main/reinforcement_learning/actor_critic.py """ import argparse import gym import numpy as np from itertools import count from collections import namedtuple import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.distributions import Categorical # 设置参数 parser = argparse.ArgumentParser(description='PyTorch actor-critic example') parser.add_argument('--gamma', type=float, default=0.99, metavar='G', help='discount factor (default: 0.99)') parser.add_argument('--seed', type=int, default=543, metavar='N', help='random seed (default: 543)') parser.add_argument('--render', action='store_true', help='render the environment') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='interval between training status logs (default: 10)') args = parser.parse_args() # 初始化 gym env = gym.make('CartPole-v1') env.seed(args.seed) torch.manual_seed(args.seed) # ln(action probability), critic value SavedAction = namedtuple('SavedAction', ['log_prob', 'value']) # Actor 和 Critic 共用网络 class Policy(nn.Module): def __init__(self): super(Policy, self).__init__() # 共用输入层 self.affine1 = nn.Linear(4, 128) # Actor 层 self.action_head = nn.Linear(128, 2) # Critic 层 self.value_head = nn.Linear(128, 1) # 一次模拟下保存的所有 action and reward self.saved_actions = [] self.rewards = [] # Network forward def forward(self, x): x = F.relu(self.affine1(x)) # Actor 层使用 softmax 让概率0~1分布,提高准确率。输出每个动作的概率 action_prob = F.softmax(self.action_head(x), dim=-1) # Critic 层输出得分 state_values = self.value_head(x) # 输出 Actor and Critic 网络 return action_prob, state_values # 初始化网络相关设置 model = Policy() optimizer = optim.Adam(model.parameters(), lr=3e-2) eps = np.finfo(np.float32).eps.item() # 使用 Categorical 包对 action 进行选择,并保存 ln(action probability) 至网络 def select_action(state): state = torch.from_numpy(state).float() probs, state_value = model(state) # 创建 categorical distribution m = Categorical(probs) # 提取 sample action = m.sample() # 保存数据至 action buffer model.saved_actions.append(SavedAction(m.log_prob(action), state_value)) # 输出 action (left or right) return action.item() # 当完成一个循环后训练网络,详情可参考以下网站 """ https://blog.csdn.net/qq_30615903/article/details/80774384 """ def finish_episode(): R = 0 saved_actions = model.saved_actions # Actor loss : - \frac { 1 } { n } \sum _ { i = 1 } ^ { n } A _ { \pi } ( s , a ) \log \pi ( s , a ) policy_losses = [] # Critic loss : \frac { 1 } { n } \sum _ { i = 1 } ^ { n } e _ { i } ^ { 2 } value_losses = [] # 策略动作值函数 : Q_{\pi}(s,a) = R_{s}^{a}+\gamma V_{\pi}(s\prime) returns = [] # calculate the true value using rewards returned from the environment for r in model.rewards[::-1]: # calculate the discounted value R = r + args.gamma * R returns.insert(0, R) returns = torch.tensor(returns) returns = (returns - returns.mean()) / (returns.std() + eps) for (log_prob, value), R in zip(saved_actions, returns): # A _ { \pi } ( s , a ) = Q _ { \pi } ( s , a ) - V _ { \pi } ( s ) = r + \gamma V _ { \pi } ( s \prime ) - V _ { \pi } ( s ) advantage = R - value.item() # calculate actor (policy) loss policy_losses.append(-log_prob * advantage) # calculate critic (value) loss using L1 smooth loss value_losses.append(F.smooth_l1_loss(value, torch.tensor([R]))) # sum up all the values of policy_losses and value_losses loss = (torch.stack(policy_losses).sum() + torch.stack(value_losses).sum()) / len(model.rewards) # 训练老三步 optimizer.zero_grad() loss.backward() optimizer.step() # reset rewards and action buffer del model.rewards[:] del model.saved_actions[:] def main(): running_reward = 10 # 无限循环 for i_episode in count(1): # 重置 env state = env.reset() ep_reward = 0 # 设置 9999 step , 防止无限循环 for t in range(1, 10000): # select action from policy action = select_action(state) # take the action state, reward, done, _ = env.step(action) if args.render: env.render() model.rewards.append(reward) ep_reward += reward if done: break # 更新总体 reward running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward # 训练网络 finish_episode() # 打印结果 if i_episode % args.log_interval == 0: print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format( i_episode, ep_reward, running_reward)) # 训练结束退出循环 if running_reward > env.spec.reward_threshold: print("Solved! Running reward is now {} and " "the last episode runs to {} time steps!".format(running_reward, t)) break if __name__ == '__main__': main() |
A2C A3C
网上多数认为 DDPG TD3 PPO 优于 A3C 所以我没怎么看此两种方法。简单来说就是通过多线程同时计算多个网络,返回组合来更新策略和值函数来更新网络。
DDPG
TD3
强化学习算法选择
关于GA/NSGA优化神经网络
查了网上一些论文和代码,自己写了三个版本的GA-BP优化代码。
说明:主要便于方便代入自己的数据所以写了如下代码。自己用的时候主要可以修改Net中的网络,Train中的load_data变成自己要读的文件,选用合适的损失函数等等。geatpy为国内大佬写的遗传算法库,这里假设读者已经会用。关于GA和NSGA的区别只在于代码中运用模板的区别。
代码都有注释,可以试着读一读。代码gpu支持暂没测试与优化。
可供测试data文件。测试文件说明:最后一列为label,除最后一列外为data。
三个版本对比,对上述测试文件对R^2 >= 0.96为指标,在我的破电脑上运行时间v1.0≈1min,v2.0约等于45s,v3.0≈20s,我没有测试过别的例子的速度,对于v3.0不能保证每个例子都能用,有一定缺陷,不同问题可以选用不同的版本进行使用。
利用 GA 求神经网络最优的learning rate和隐藏层的神经元个数
GA-NET v1.0
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
import torch.nn as nn import torch import geatpy as ea import numpy as np import os from sklearn.model_selection import train_test_split input_dimension = 7 output_dimension = 1 # 自定义网络 class Net(nn.Module): def __init__(self, neurons_num): super(Net, self).__init__() self.hidden0 = torch.nn.Linear(input_dimension, neurons_num) self.hidden1 = torch.nn.Linear(neurons_num, neurons_num) self.hidden2 = torch.nn.Linear(neurons_num, neurons_num) self.hidden3 = torch.nn.Linear(neurons_num, output_dimension) def forward(self, x): x = torch.relu(self.hidden0(x)) x = torch.relu(self.hidden1(x)) x = torch.relu(self.hidden2(x)) x = self.hidden3(x) return x # r^2 函数 def r2(y_test, y): return 1 - ((y_test - y) ** 2).sum() / ((y.mean() - y) ** 2).sum() # 神经网络训练 class Train: train_x, train_y, test_x, test_y, model, lr, neurons_num, x, y, optimizer = None, None, None, None, None, None, None, None, None, None def __init__(self): self.use_gpu = torch.cuda.is_available() # 选用合适的 loss function # self.loss_fn = torch.nn.CrossEntropyLoss() self.loss_fn = torch.nn.MSELoss() self.load_data() # 自定义读入数据 def load_data(self): with open('data.csv') as f: df = np.loadtxt(f, delimiter=",", skiprows=0) self.x = df[:, :-1] self.y = df[:, -1:] f.close() # 重新创建不一样的 train and test data set def reload(self, learing_rate, neurons_num): train_x, test_x, train_y, test_y = train_test_split(self.x, self.y, test_size=0.3, random_state=42) self.train_x = torch.from_numpy(train_x).float() self.train_y = torch.from_numpy(train_y).float() self.test_x = torch.from_numpy(test_x).float() self.test_y = torch.from_numpy(test_y).float() self.model = Net(neurons_num) if self.use_gpu: self.train_x, self.train_y, self.test_x, self.test_y = self.train_x.cuda(), self.train_y.cuda(), self.test_x.cuda(), self.test_y.cuda() self.model = self.model.cuda() self.loss_fn = self.loss_fn.cuda() self.lr = learing_rate self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr) # 训练神经网络,返回 r^2 值 def train(self, n=10): for epoch in range(n): model_output = self.model(self.train_x) loss = self.loss_fn(model_output, self.train_y) self.optimizer.zero_grad() loss.backward() self.optimizer.step() model_output = self.model(self.test_x) return float(r2(model_output.data, self.test_y)) # 自定义 GA,对 learning rate and neurons num 经行改变 class My_nsga(ea.Problem): def __init__(self, epoch): if "result" not in os.listdir(): os.makedirs("./result") name = 'GA-NET' M = 1 maxormins = [-1] * M Dim = 2 varTypes = [1] * Dim lb = [10, 10] ub = [5000, 100] lbin = [1] * Dim ubin = [1] * Dim self.epoch = epoch self.train = Train() ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin) # 目标函数即神经网络返回值 def evalVars(self, Vars): ans = np.zeros(len(Vars), dtype=float).reshape(len(Vars), 1) for i in range(len(Vars)): self.train.reload(Vars[i][0] / 100000, Vars[i][1]) # 括号内参数表示单个神经网络训练次数 data = self.train.train(self.epoch) print("learning rate = {}, neurons num = {}, R^2 = {}".format(Vars[i][0] / 10000, Vars[i][1], data)) torch.save(self.train.model, "./result/lr={}num={}epoch={}r2={}.pt".format(Vars[i][0] / 100000, Vars[i][1], self.epoch, round(data, 3))) # 达到一定准确率停止 if data >= 1: torch.save(self.train.model, "lr{}=num={}epoch={}r2={}.pt".format(Vars[i][0] / 100000, Vars[i][1], self.epoch, round(data, 3))) exit("Find!") ans[i][0] = data return ans # 运行 GA class Run_nsga: def __init__(self, epoch=10, ndind=10, maxgen=10): problem = My_nsga(epoch) myAlgorithm = ea.soea_EGA_templet(problem, ea.Population(Encoding='RI', NIND=ndind), MAXGEN=maxgen, logTras=0) myAlgorithm.drawing = 0 res = ea.optimize(myAlgorithm, seed=1, verbose=False, drawing=0, outputMsg=True, drawLog=False, saveFlag=False, dirName='result') print(res) print(res['Vars'][0]) if __name__ == "__main__": # 括号内参数表示单个神经网络训练次数,种群数,GA迭代数 Run_nsga(10000, 10, 30) |
对于图片的识别,进行了相关优化
GA-NET v2.0
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 |
import torch.nn as nn import torch import geatpy as ea import numpy as np import os from sklearn.model_selection import train_test_split input_dimension = 7 output_dimension = 1 batch_size = 500 # 自定义网络 class Net(nn.Module): def __init__(self, neurons_num): super(Net, self).__init__() self.hidden0 = torch.nn.Linear(input_dimension, neurons_num) self.hidden1 = torch.nn.Linear(neurons_num, neurons_num) self.hidden2 = torch.nn.Linear(neurons_num, neurons_num) self.hidden3 = torch.nn.Linear(neurons_num, output_dimension) def forward(self, x): x = torch.relu(self.hidden0(x)) x = torch.relu(self.hidden1(x)) x = torch.relu(self.hidden2(x)) x = self.hidden3(x) return x # r^2 函数 def r2(y_test, y): return 1 - ((y_test - y) ** 2).sum() / ((y.mean() - y) ** 2).sum() # Data 类,以便带入自己的data class Data(torch.utils.data.Dataset): def __init__(self, data, label): # 可选择归一化操作 # data = (data - data.min(axis=0)) / (data.max(axis=0) - data.min(axis=0)) # label = (label - label.min(axis=0)) / (label.max(axis=0) - label.min(axis=0)) self.x = data self.y = label self.len = len(self.y) def __len__(self): return self.len def __getitem__(self, item): return self.x[item], self.y[item] # 神经网络训练 class Train: trainsetloader, test_x, test_y, model, lr, neurons_num, optimizer, x, y = None, None, None, None, None, None, None, None, None def __init__(self): self.use_gpu = torch.cuda.is_available() # 选用合适的 loss function # self.loss_fn = torch.nn.CrossEntropyLoss() self.loss_fn = torch.nn.MSELoss() self.load_data() # 自定义读入数据 def load_data(self): with open('data.csv') as f: df = np.loadtxt(f, delimiter=",", skiprows=0) self.x = df[:, :-1] self.y = df[:, -1:] f.close() # 创建 train and test self.re_data_split() # 重新创建不一样的 train and test data set,便于带入到 reload 函数中 def re_data_split(self): train_x, test_x, train_y, test_y = train_test_split(self.x, self.y, test_size=0.3, random_state=42) train_x = torch.from_numpy(train_x).float() train_y = torch.from_numpy(train_y).float() # test 数据 self.test_x = torch.from_numpy(test_x).float() self.test_y = torch.from_numpy(test_y).float() trainset = Data(train_x, train_y) # train 池化 self.trainsetloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=False) # 重新载入 learning rate 和 neurons num def reload(self, learning_rate, neurons_num): # 可选择是否重新分类 test and train # self.re_data_split() self.model = Net(neurons_num) if self.use_gpu: self.model = self.model.cuda() self.loss_fn = self.loss_fn.cuda() self.lr = learning_rate self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr) # 训练神经网络,返回 r^2 值 def train(self, n=10) -> float: for epoch in range(n): for i, (batch_x, batch_y) in enumerate(self.trainsetloader): model_output = self.model(batch_x) loss = self.loss_fn(model_output, batch_y) self.optimizer.zero_grad() loss.backward() self.optimizer.step() model_output = self.model(self.test_x) print(float(r2(model_output.data, self.test_y))) model_output = self.model(self.test_x) return float(r2(model_output.data, self.test_y)) # 自定义 GA,对 learning rate and neurons num 经行改变 class My_nsga(ea.Problem): def __init__(self, epoch): if "result" not in os.listdir(): os.makedirs("./result") name = 'GA-NET' M = 1 maxormins = [-1] * M Dim = 2 varTypes = [1] * Dim lb = [10, 10] ub = [500, 100] lbin = [1] * Dim ubin = [1] * Dim self.count = 1 self.epoch = epoch self.train = Train() ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin) # 目标函数即神经网络返回值 def evalVars(self, Vars): ans = np.zeros(len(Vars), dtype=float).reshape(len(Vars), 1) for i in range(len(Vars)): self.train.reload(Vars[i][0] / 100000, Vars[i][1]) # 括号内参数表示单个神经网络训练次数 data = self.train.train(self.epoch) print("learning rate = {}, neurons num = {}, R^2 = {}".format(Vars[i][0] / 10000, Vars[i][1], data)) torch.save(self.train.model, "./result/lr={}num={}epoch={}r2={}.pt".format(Vars[i][0] / 100000, Vars[i][1], self.epoch, round(data, 3))) # 达到一定准确率停止 if data >= 1: torch.save(self.train.model, "lr{}=num={}epoch={}r2={}.pt".format(Vars[i][0] / 100000, Vars[i][1], self.epoch, round(data, 3))) exit("Find!") ans[i][0] = data return ans # 运行 GA class Run_nsga: def __init__(self, epoch=10, ndind=10, maxgen=10): problem = My_nsga(epoch) myAlgorithm = ea.soea_EGA_templet(problem, ea.Population(Encoding='RI', NIND=ndind), MAXGEN=maxgen, logTras=0) myAlgorithm.drawing = 0 res = ea.optimize(myAlgorithm, seed=1, verbose=False, drawing=0, outputMsg=True, drawLog=False, saveFlag=False, dirName='result') print(res) print(res['Vars'][0]) if __name__ == "__main__": # 括号内参数表示单个神经网络训练次数,种群数,GA迭代数 Run_nsga(10000, 10, 30) |
在神经网络中也加入GA来加快神经网络训练速度
GA-NET v3.0
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 |
import random import torch.nn as nn import torch import geatpy as ea import numpy as np import os import copy from sklearn.model_selection import train_test_split from torch.distributions import Categorical input_dimension = 7 output_dimension = 1 # 该参数在数据较少的输入时也相应变少,最好使得 data_size / batch_size = NetGA_pop_size batch_size = 100 # 自定义网络 class Net(torch.nn.Module): def __init__(self, neurons_num, lr): super(Net, self).__init__() self.layers = torch.nn.Sequential( torch.nn.Linear(input_dimension, neurons_num), torch.nn.ReLU(), torch.nn.Linear(neurons_num, neurons_num), torch.nn.ReLU(), torch.nn.Linear(neurons_num, neurons_num), torch.nn.ReLU(), torch.nn.Linear(neurons_num, output_dimension) ) self.optimizer = torch.optim.Adam(self.parameters(), lr=lr) def forward(self, x): return self.layers(x) def set_layer(self, layers): self.layers = layers # r^2 函数 def r2(y_test, y): return 1 - ((y_test - y) ** 2).sum() / ((y.mean() - y) ** 2).sum() # Data 类,以便带入自己的data class Data(torch.utils.data.Dataset): def __init__(self, data, label): self.x = data self.y = label self.len = len(self.y) def __len__(self): return self.len def __getitem__(self, item): return self.x[item], self.y[item] # GA 优化的神经网络训练 class NetTrainGA: def __init__(self, _pop_size=10, _r_mutation=0.1, _p_mutation=0.1, _elite_num=6, stddev=0.1): self.test_x, self.test_y, self.trainSetLoader, self.x, self.y = None, None, None, None, None # 数据存储 self.pop_size = _pop_size # 种群数 self.r_mutation = _r_mutation # 变异里,数据变异的概率 self.p_mutation = _p_mutation # 变异概率 self.elite_num = _elite_num # 精英数 self.chroms = [] # 储存所有 model self.stddev = stddev # 网络权值步进大小的最大值 self.criterion = nn.MSELoss() # 计算 loss 的方法 self.model = None # 全局最优解 model self.use_gpu = torch.cuda.is_available() # 是否可以用 cuda 加速 self.load_data() # 加载数据 self.lr = 0.001 # learning rate # 自定义读入数据 def load_data(self): with open('data.csv') as f: df = np.loadtxt(f, delimiter=",", skiprows=0) self.x = df[:, :-1] self.y = df[:, -1:] f.close() # 创建 train and test self.re_data_split() # 重新创建不一样的 train and test data set,便于带入到 reload 函数中 def re_data_split(self): train_x, test_x, train_y, test_y = train_test_split(self.x, self.y, test_size=0.3, random_state=42) train_x = torch.from_numpy(train_x).float() train_y = torch.from_numpy(train_y).float() # test 数据 self.test_x = torch.from_numpy(test_x).float() self.test_y = torch.from_numpy(test_y).float() trainSet = Data(train_x, train_y) # train 池化 self.trainSetLoader = torch.utils.data.DataLoader(trainSet, batch_size=batch_size, shuffle=False) def reload(self, learning_rate, neurons_num): # 可选择是否重新分类 test and train # self.re_data_split self.lr = learning_rate for i in range(self.pop_size): net = Net(neurons_num, learning_rate) if self.use_gpu: net = net.cuda() self.chroms.append(net) # 训练神经网络,返回R^2的值 """ 对下列博客代码进行改进 https://blog.csdn.net/Vertira/article/details/122561056 """ def train(self, n): for epoch in range(n): result = [{'pop': i, 'train_acc': float("-inf")} for i in range(self.pop_size)] # 为种群训练不同的数据 for step, (batch_x, batch_y) in enumerate(self.trainSetLoader): self.netTrain(batch_x, batch_y, (step + epoch) % self.pop_size) # 计算 train accuracy for i in range(self.pop_size): output = self.chroms[i](self.test_x) result[i]["train_acc"] = float(r2(output.data, self.test_y)) result = sorted(result, key=lambda x: x['train_acc'], reverse=True) # self.model 即为类中最优解,可直接套用 test 经行预测 self.model = self.chroms[result[0]['pop']] self.selection(result) # 类比精加工,提高准确率,参数可调,可选操作,不想这一步可以注释掉,实践证明有这一步不一定更好 self.fine_train(n * 50) model_output = self.model(self.test_x) return float(r2(model_output.data, self.test_y)) # 网络精细化训练 def fine_train(self, n=1000): # 防止本来梯度就消失 self.model.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr) for epoch in range(n): for i, (batch_x, batch_y) in enumerate(self.trainSetLoader): model_output = self.model(batch_x) loss = self.criterion(model_output, batch_y) self.model.optimizer.zero_grad() loss.backward() self.model.optimizer.step() def netTrain(self, batch_x, batch_y, now): model = self.chroms[now] optimizer = model.optimizer # 选择每次神经网络训练次数,这个参数影响了训练速度,但跟多时候会影响梯度,很多时候我也不知道为什么梯度就没了,所以太小梯度可能变0或None导致训练停滞,太大训练的有可能变慢 for j in range(100): output = model(batch_x) optimizer.zero_grad() train_loss = self.criterion(output, batch_y).requires_grad_() train_loss.backward() optimizer.step() # 保留精英个数,并进行交叉操作至种群数满,最后进行变异操作 def selection(self, result): elites = [e['pop'] for e in result[:self.elite_num]] # 保留 elites 个精英 children = [copy.deepcopy(self.chroms[i]) for i in elites] # 轮盘赌来选择交配的个体,使用 softmax 处理负数问题 prob = torch.softmax(torch.tensor([i["train_acc"] for i in result]), dim=0) m = Categorical(prob) # 随机选择两个交配直至达到种群大小 while len(children) < self.pop_size: # 随机选择两个进行 self.crossover交配 pair = [result[m.sample()]['pop'], result[m.sample()]['pop']] children.append(self.crossover(pair)) del self.chroms[:] self.chroms[:] = children # 变异且不变异精英 for i in range(self.elite_num, self.pop_size): # 满足变异概率 if random.random() < self.p_mutation: mutated_child = self.mutation(i) del self.chroms[i] self.chroms.insert(i, mutated_child) def crossover(self, _selected_pop): if _selected_pop[0] == _selected_pop[1]: return copy.deepcopy(self.chroms[_selected_pop[0]]) chrom1 = copy.deepcopy(self.chroms[_selected_pop[0]]) chrom2 = copy.deepcopy(self.chroms[_selected_pop[1]]) chrom1_layers = nn.ModuleList(chrom1.modules()) chrom2_layers = nn.ModuleList(chrom2.modules()) child = torch.nn.Sequential() for i in range(len(chrom1_layers)): layer1 = chrom1_layers[i] layer2 = chrom2_layers[i] # 对 Linear 层随机交换 if isinstance(layer1, nn.Linear): child.add_module(str(i - 2), layer1 if random.random() < 0.5 else layer2) elif isinstance(layer1, (torch.nn.Sequential, Net)): pass else: child.add_module(str(i - 2), layer1) chrom1.set_layer(child) chrom1.optimizer = torch.optim.Adam(chrom1.parameters(), lr=self.lr) return chrom1 def mutation(self, _selected_pop): child = torch.nn.Sequential() chrom = copy.deepcopy(self.chroms[_selected_pop]) chrom_layers = nn.ModuleList(chrom.modules()) # 变异比例,选择几层进行变异 for i, layer in enumerate(chrom_layers): if isinstance(layer, nn.Linear): # 变异 Linear 层,且有一定变异比例 if random.random() < self.r_mutation: # 提取权重 weights = layer.weight.detach().numpy() # 更改权重 w = weights.astype(np.float32) + np.random.normal(0, self.stddev, weights.shape).astype(np.float32) # 重新设置 layer.weight = torch.nn.Parameter(torch.from_numpy(w)) child.add_module(str(i - 2), layer) elif isinstance(layer, (torch.nn.Sequential, Net)): pass else: child.add_module(str(i - 2), layer) chrom.set_layer(child) chrom.optimizer = torch.optim.Adam(chrom.parameters(), lr=self.lr) return chrom # 自定义 GA,对 learning rate and neurons num 经行改变 class My_nsga(ea.Problem): def __init__(self, epoch): if "result" not in os.listdir(): os.makedirs("./result") name = 'GA-NET' M = 1 maxormins = [-1] * M Dim = 2 varTypes = [1] * Dim lb = [10, 10] ub = [500, 100] lbin = [1] * Dim ubin = [1] * Dim self.count = 1 self.epoch = epoch self.train = NetTrainGA() ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin) # 目标函数即神经网络返回值 def evalVars(self, Vars): ans = np.zeros(len(Vars)).reshape(len(Vars), 1) for i in range(len(Vars)): self.train.reload(Vars[i][0] / 10000, Vars[i][1]) # 括号内参数表示单个神经网络训练次数 data = self.train.train(self.epoch) print("learning rate = {}, neurons num = {}, R^2 = {}".format(Vars[i][0] / 10000, Vars[i][1], round(data, 3))) torch.save(self.train.model, "./result/lr{}num{}epoch{}r2{}.pt".format(Vars[i][0] / 10000, Vars[i][1], self.epoch, round(data, 3))) # 达到一定准确率停止 if data >= 1: torch.save(self.train.model, "lr{}num{}epoch{}r2{}.pt".format(Vars[i][0] / 10000, Vars[i][1], self.epoch, round(data, 3))) return 0 ans[i] = float(data) return ans # 运行 GA class Run_nsga: def __init__(self, epoch=10, ndind=10, maxgen=10): problem = My_nsga(epoch) myAlgorithm = ea.soea_EGA_templet(problem, ea.Population(Encoding='RI', NIND=ndind), MAXGEN=maxgen, logTras=0) myAlgorithm.drawing = 0 res = ea.optimize(myAlgorithm, seed=1, verbose=False, drawing=0, outputMsg=True, drawLog=False, saveFlag=False, dirName='result') print(res) print(res['Vars'][0]) if __name__ == "__main__": # 括号内参数表示单个神经网络训练次数,种群数,GA迭代数 Run_nsga(100, 10, 10) """ # 也可以单独调用 NetTrainGA,设置初始参数 netga = NetTrainGA() # learning rate, neurons_num netga.reload(0.001, 30) # epoch print(netga.train(1000)) """ |
以上均为回归损失计算方法,要计算分类损失只需要修改如下代码。
分类损失
|
1 2 3 4 5 6 7 8 9 10 |
# 修改 y 维度 self.y = df[:, -1] # 修改损失函数 self.criterion = nn.CrossEntropyLoss() # 修改 train_y 从 float 变成 long train_y = torch.from_numpy(train_y).long() # 修改 train_acc 计算方法 result[i]["train_acc"] = float((output.argmax(dim=1) == self.test_y).sum()) / len(self.test_y) # 修改 train 输出 return (model_output.argmax(dim=1) == self.test_y).sum() / len(self.test_y) |
 浙公网安备 33010902002953号
浙公网安备 33010902002953号